DHCP leases history application
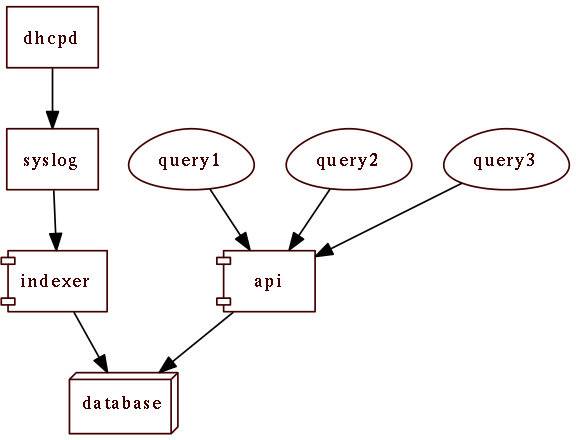
Anton Berezin <tobez@tobez.org>
Malmö, June 2011
| Column | Type |
|---|---|
| ip | varchar(15) |
| circuit_number | varchar(64) |
| start | integer (UNIX time) |
| stop | integer (UNIX time) |
| service_type | varchar(32) |
| access_type | varchar(32) |
| mac | varchar(20) |
Jun 17 06:25:18 \
111.222.33.44 radiusd[12345]: \
DHCPUSER 11.22.33.44 on CN-123456 \
duration 1800 \
service-type Internet \
access-type DSL \
mac 01:02:03:04:05:06
About a hundred such lines a second.
nownowstart_time to end_timestart_time to end_timenow
telnet or nc can be a client as wellFrom http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis, a comparison of various NoSQL databases:
Best used: For rapidly changing data with a foreseeable database size (should fit mostly in memory).
Our case:
use Redis;
my $rd = Redis->new(encoding => undef);
for my $k (1..100000) {
$rd->set("key_$k", rand);
}
say $rd->get("key_4242");
say join ", ", $rd->keys("*_4242*");0.634714091076177
key_42420, key_42421, key_42422, key_42423,
key_42424, key_42425, key_42426, key_42427,
key_42428, key_42429, key_4242
Takes 12 seconds = handles more than 8k sets/sec on my desktop.
use Redis;
my $rd = Redis->new;
$rd->hset("hashname", field => "value");
$rd->hmset("hashname", first_name => "John",
last_name => "Doe", age => 20);
if ($rd->hexists("hashname", "first_name")) {
say "Hi, ", $rd->hget("hashname", "first_name");
}
$rd->hdel("hashname", "field");
$rd->hincrby("hashname", "age", 22);
say "keys: ", join ", ", $rd->hkeys("hashname");
say "vals: ", join ", ", $rd->hvals("hashname");
say "name: ", join " ", $rd->hmget("hashname",
"first_name", "last_name");Hi, John
keys: first_name, last_name, age
vals: John, Doe, 42
name: John Doe
my $rd = Redis->new;
$rd->rpush("mylist", "value");
$rd->lpush("mylist", "Hello");
$rd->linsert("mylist", "before", "value", "World");
$rd->lset("mylist", 1, "Sweden");
say $rd->lindex("mylist", 2);
say $rd->rpop("mylist");
say join ", ", $rd->lrange("mylist", 0, -1);value
value
Hello, Sweden
$rd->sadd("myset", "red");
$rd->sadd("myset", "green");
$rd->sadd("myset", "green");
$rd->sadd("myset", "green");
$rd->sadd("myset", "blue");
$rd->sadd("myset", "supernova");
say $rd->sismember("myset", "supernova");
$rd->srem("myset", "supernova");
say $rd->scard("myset");
say join ", ", $rd->smembers("myset");
say $rd->srandmember("myset");
# unions, intersections, differences1
3
red, blue, green
red
multi/watch/exec comboUsed for sequence emulation.
my $rd = Redis->new;
say $rd->incr("myseq");
sleep 5;
say $rd->incr("myseq");1
5
(Obviously, something else was doing INCR at the time)
if ($rd->setnx("mylock", "can lock")) {
say "We can lock!";
# do stuff
sleep 5;
$rd->del("mylock");
} else {
say "Sorry, already locked"
}There is a problem if the process dies in between;
this can be worked around with more code.
In the latest versions of Redis there is a support for check-and-set transactions.
Unfortunately, it seems that CPAN modules have not caught up yet.

Well, thankfully not quite.
Redis provides two mechanisms to keep your data safe.
save 900 1
save 300 10
save 60 10000
set x 42
set x 666
set x 42
BGREWRITEAOF command
BGREWRITEAOF is typically run from cron
*/5 * * * * echo BGREWRITEAOF | redis-cli >/dev/nullSELECT * FROM leases
WHERE ip = '11.22.33.44'
ORDER BY stop DESC
LIMIT 1UPDATE leases
SET
stop = 1308344787,
service_type = 'Internet',
access_type = 'DSL',
mac = '01:02:03:04:05:06'
WHERE
ip = '11.22.33.44' AND
circuit_number = 'CN-123456' AND
start = 1308344185The "expire latest" op is implemented in terms of "update" as well.
INSERT into leases
(ip, circuit_number,
start, stop,
service_type, access_type
mac) VALUES (
'11.22.33.44',
'CN-123456',
1308344185,
1308344787,
'Internet',
'DSL',
'01:02:03:04:05:06')SELECT * FROM leases
WHERE
ip = '11.22.33.44' AND
stop >= 1308344185 AND
1308344185 >= startSELECT * FROM leases
WHERE
circuit_number = 'CN-123456' AND
stop >= 1308344185 AND
1308344185 >= startSELECT * FROM leases
WHERE
ip = '11.22.33.44' AND
stop >= 1308344185 AND
1308399185 >= startSELECT * FROM leases
WHERE
circuit_number = 'CN-123456' AND
stop >= 1308344185 AND
1308399185 >= startDELETE FROM leases
WHERE stop < 1276863185"1 year ago"
key: ip:11.22.33.44
type: string
value: CN-193688 1307003895 1308427546 Internet DSL 01:02:de:ad:be:ef
key: cn:CN-193688
type: set
values:
1. 11.22.33.44
2. 10.235.75.143
3. 10.13.94.142
key: hip:11.22.33.44
type: string
value:
CN-180676 1303078615 1303338407 IPTV DSL 01:02:03:04:fe:ef\n
CN-186104 1304247778 1305890933 IPTV DSL 01:02:03:04:f0:0f\n
etc.
Need to clean old values somehow.
key: hcn:CN-180676
type: string
value:
11.22.33.44 1303078615 1303338407 IPTV DSL 01:02:03:04:fe:ef\n
22.33.44.11 1300572400 1300577082 Internet DSL 01:08:22:33:ee:dd\n
etc.
Again, need to clean old values somehow.
my $ip = "11.22.33.44";
my $s = $rd->get("ip:$ip");
return undef unless $s;
my ($cn, $start, $end, $st, $at, $mac) = split / /, $s;
return {
ip => $ip,
cn => $cn,
start => $start,
end => $end,
service_type => $st,
access_type => $at,
mac => $mac,
};$rd->set("ip:$ip", "$cn $start $end $st $at $mac");
$rd->sadd("cn:$ip", "$ip $start $end $st $at $mac");Two Redis operations. No need for locking, single updater. Can be extended to multiple updaters if we guarantee disjoint IP set.
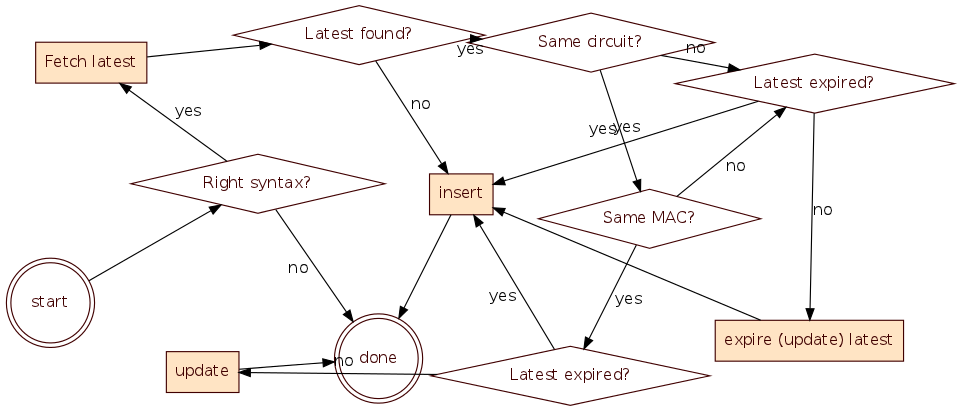
Note: "insert" is identical to "update".
my $hip = $rd->get("hip:$ip");
my $ip_info = "$cn $start $end $st $at $mac";
$hip = $hip ? "$hip\n$ip_info" : $ip_info;
$rd->set("hip:$ip", $hip);
my $hcn = $rd->get("hcn:$cn");
my $cn_info = "$ip $start $end $st $at $mac";
$hcn = $hcn ? "$hcn\n$cn_info" : $cn_info;
$rd->set("hcn:$cn", $hcn);
$rd->srem("cn:$cn", $ip);
$rd->del("ip:$ip");undefnow is not between start and stopmy @ips = $rd->smembers("cn:$cn");
my $now = time;
my @r;
for my $ip (@ips) {
my $info = $rd->get("ip:$ip");
next unless $info;
my ($cn2, $start, $stop, $st, $at, $mac) = split / /, $info;
next unless $cn eq $cn2;
next unless $start <= $now && $stop >= $now;
push @c, {
ip => $ip,
service_type => $st,
access_type => $at,
mac => $mac,
};
}"ip:$ip""hip:$ip", split by "\n""cn:$cn", fetching their info"hcn:$cn", split by "\n"For a while, run two indexers in parallel and do the checks on the data generated by the Redis one.
Do the queries against both DB and Redis.
But don't return results of the Redis queries to the user yet.
In our case, this is an easy step:
A simple message sender:
$rd->publish("ch1", "message to ch1");
$rd->publish("ch2", "something to ch2");
$rd->publish("ch1", "quit");my $quit = 0;
$rd->subscribe("ch1", sub {
my $msg = shift;
print "$msg\n";
$quit = 1 if $msg eq "quit";
});
$rd->wait_for_messages(1) until $quit;message to ch1
quit
my $quit = 0;
$rd->psubscribe("ch*", sub {
my $msg = shift;
print "$msg\n";
$quit = 1 if $msg eq "quit";
});
$rd->wait_for_messages(1) until $quit;message to ch1
something to ch2
quit
Emulate them!
There is a feature in Redis which I did not talk about yet.
It can be made to expire keys.
my $rd = Redis->new;
$rd->setex("mykey", 3, 42); # 3 seconds
say $rd->get("mykey");
sleep(1);
say $rd->ttl("mykey");
sleep(3);
say $rd->get("mykey");42
2
(undef)
Request tracker is instrumented to put JSON-encoded transactions into Redis:
The code for populating $val is too large to fit on this margin screen.
my $val = {...};
my $seq = $rd->incr("seq-tr");
my $key = "tr:$seq";
$rd->set($key, encode_json($val));
$rd->expire($key, 3600);TART, to do the heavy liftingTART instances provide an iterator-like interface:my $tart = TART->new("interested-party");
while (my $transaction = $tart->next) {
# do something with %$transaction hash
# which is the same as %$val on the previous slide
}
# register last processed transaction for "interested-party"
$tart->commit;sub new
{
my ($class, $id) = @_;
# $id == "interested-party" in our example
return bless { id => $id }, $class;
}sub next
{
my $me = shift;
$me->_fetch unless $me->{rd};
while (@{$me->{keys}}) {
my $k = shift @{$me->{keys}};
my $v = $me->{rd}->get("tr:$k");
if ($v) {
$me->{last_seen} = $k;
return decode_json(Encode::encode("utf-8", $v));
}
}
return undef;
}sub _fetch
{
my $me = shift;
$me->{rd} = Redis->new;
$me->{last_seen} =
$me->{rd}->get("tart:daemon:last:$me->{id}") || 0;
$me->{keys} = [
sort { $a <=> $b }
grep { $_ > $me->{last_seen} }
map { /^tr:(\d+)$/ ? ($1) : () }
$me->{rd}->keys("tr:*")
];
}sub commit
{
my $me = shift;
$me->_fetch unless $me->{rd};
$me->{rd}->set("tart:daemon:last:$me->{id}",
$me->{last_seen});
}
